
Natural Selection 2 is my favorite game, without compare. I really can’t say enough good things about it, go watch the last big tournament if you want a taste. It combines everything that’s great about the FPS and RTS genres, and requires very high levels of FPS skill, RTS tactics, and team coordination to play well. It’s the only video game I’ve played where a person’s leadership skills can mean the difference between victory and defeat. When someone leads their team to victory in NS2, it doesn’t mean they were the one with the most kills. It’s a very rewarding social experience, with all the highs and lows of a team sport, but you get to shoot aliens.
It is however, a difficult game to learn, and an even more difficult game to play well. Because of this, games in public servers often have unbalanced teams, leading to dissatisfying games for both sides.
To help fix this problem, I designed a player ranking system that was implemented in the most recent patch, Build 267. It’s based on skill systems like ELO but tweaked for the unique properties of NS2.
Overview
A useful skill system should be able to predict the outcome of a game using the skills of the players on each team. Rather than trying to figure out which other statistics about a player (kill/death etc) indicate that a player is good, we instead try to infer it the skill levels just from our original objective: predicting the outcome of games.
Designing a skill system like this is different from many other statistics problems, because the world changes in response to the system. It’s not enough to predict the outcome of games, you have to be sure that you can still predict the outcome of games even when people know how your system works. On top of that, you have to ensure that your system incentivizes behaviors that are good for the game.
Notation
is the probability of a victory by team 1.
is the outcome of the game, 1 if team 1 wins, 0 if team 1 loses.
is the skill of the
th player.
is the time spent in the round, an exponential weighting of each second so that being in the round at the beginning counts more than being in the round at the end. Integrals over exponents are easy, so you can implement this as
. Set
to something like
where
is the median round length. This means that playing until the middle of an average round counts more than playing from the middle to the end, no matter how long the round takes.
is an indicator variable for the team of the
The Basic Model
To compute the skill values, the first task is to predict the probability of team 1 winning the round as a function of those skill values.


The function 


We’d like to come up with the values for

We predict the outcome of the game based on the players’ skill and how long they each played in the game. After the game, we update each player’s skill by the product of what fraction of the game they played, and the difference between our prediction and what actually happened.
Properties of the Basic Model
- If one team smashes another, but the teams were stacked to make that outcome almost certain, nobody’s skill level changes at the end of the round. Only unexpected victories change skill levels.
- Nothing you do during the round other than winning the game has any effect on your skill level. This means that there’s no incentive to rack up kills at the end of the game rather than finishing it, or to play skulk instead of gorge, or to go offense rather than build.
- The effect on your score is determined by the time you spent playing the round rather than your points, with the beginning of the game weighted much higher than the end. This means that it doesn’t harm you to join a game that is already lost, because you’ll have played for a very small fraction of the weighted time spent in the game.
- If the two teams have a different number of players, this is compensated for automatically by normalizing by the total time across both teams rather than just within a team, and the model predicts that the team with more players will win.
- Larger games contribute less to each player’s skill level because the presumption is that each player has a smaller effect on the outcome of the game.
- If you are a highly skilled player on a low-skill server, the best thing you can do for your skill ranking is to join the underdog team, and lead them to victory.
Accounting for imbalance in races, maps, game sizes.
The basic model assumes that the only factors that contribute to the outcome of the game are the skill of the players. Given the overall win rate of each race, this is clearly not true. To fix the model to account for this, all we have to change is our original formula for p.

We can determine the value of 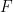

This needn’t be merely a function of the race however. It could also be a function of the map, the game size, or any other relevant feature that is independent of the players. All that is necessary to set its value is to measure the historical winrate for the team in that set of circumstances (for instance, aliens on ns2_summit with game size > 16), and put it through the inverse logit function as above.

Learning Rate
Gradient descent tells you which direction to go, but it doesn’t tell you how far. We have a lot of freedom in choosing how much to update each player’s score after each round to make it satisfying for the player. In addition, the optimization algorithm we are using is a special case of “Stochastic Gradient Descent” which has attracted a flurry of research interest in the last few years due to its popularity in Deep Learning. Thanks to this, there’s a lot of research on how to get it to converge quickly. Our case is special in several ways. Our problem is sparse, only a small fraction of players will be updated on each game. The size of the gradients is bounded and stable. Our underlying parameters are non-stationary, but change at a relatively low rate.
To accommodate these properties, we use a blend of an Adagrad based learning rate (to achieve fast convergence) and a constant learning rate (to accommodate non-stationarity.) Despite the intimidating paper, Adagrad has a very simple formulation which has added to its popularity. Roughly speaking, the update to a player’s skill will be inversely proportional to the square root of the number of games they have played plus some constant.




In these formulas, 

Per Team Skills
The above system uses one value for each player’s skill. When players are better at one team than another, this leads to a number of issues:
- Players who play primarily with the team they are better at will have inflated skill values.
- Even when players are assigned randomly, long stretches of playing a team they are better or worse at adds noise to their skill value.
- The impact of a good player on a team is different between marines and aliens, and different at different skill levels. An excellent shot is more likely to carry the marine team than an equivalent level of skill in an alien.
- Balancing algorithms are limited in how well it can balance teams, since they are unaware of the discrepancy.
We could fix these by just separating skill into two separate values, but we’d also like our solution to have the following properties.
- It should converge in as few games as the current system. Separating skills naively would not.
- Shuffle should not force players to play on their better or worse team. If a player is generally better than average, a naive shuffle would tend to put them on their worse team.
The proposal that solves the majority of these issues, rather than learning two separate skills, is to learn an average and a difference. In addition to the common skill value used above, we’ll learn an offset that turns the average into their skill for each team when added or subtracted.


The learning rate of the skill value is the sum of two components, the AdaGrad learning rate, and the constant learning rate. To learn the correct value for this offset, while ensuring the system converges at the same rate, we will not apply the AdaGrad learning rate to the offset, only the constant learning rate. This will cause a player’s initial games to affect both skill values equally, and later games to only affect the skill for the team they played on.
The skill values this learns without the offset are backwards compatible, so balancing algorithms will not need to be modified. Despite the fact that each player will still only have one skill value for balancing, there is still a benefit to doing this. A player’s skill will no longer randomly walk based on their team assignment. It will always be the average of their marine and alien skill, rather than being effectively a weighted average of their skill for the teams they’ve played on recently. Additionally, by collecting this data, and returning it from hive, we can open it up to modders to balance teams more aggressively if they desire.
To compute this, we need to do the following. Modify the skill value used in the game prediction to be:

The gradient computation is identical to the skill gradient, but we do not use the sign of the team they played on in the computation. Winning on marines, or losing on aliens contribute the same gradient.


Aside: Why the logit and not erf?
This formulation of a skill system differs from many others in that it uses the logistic distribution’s cdf to model win probabilities rather than the gaussian distribution’s cdf. There are two reasons I chose this.
- NS2 allows for frequent upsets late in the game if one team is particularly cunning, and the other is inattentive. This makes a distribution with fatter tails more appropriate.
- Using the logit allows us to correct for various factors that cause imbalance in the game without any complicated optimization. Due to the independence assumption, we can just measure winrates empirically in different circumstances, and we don’t have to optimize these coefficients jointly with the player skill.
Fully Solving for Faster Convergence
Rather than restricting ourselves to updating the skill levels once on each game, we can optimize them iteratively using the whole history of games, which will cause them to converge much faster as we acquire more data. To do this however, it is necessary to put a prior on the skill levels of each player so that they are guaranteed to converge even when there is little data for a player. To do this, include a Gamma Distribution in the model for each player’s skill.
The gradient of the log likelihood of the gamma distribution is 

There are two differences between this formula and the update rule above. The first is that rather than just updating the score one game at a time as the games come in, we store the whole history of games the player has played, and iteratively update the player’s skill.
Secondly, on each iteration, we add 

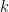
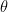
The mean skill value will be 
To run this algorithm, we alternate between updating our prediction for the outcome of each game and updating each player’s skill level based on the new predictions for all of the games they’ve played.
Special treatment for commanders.
The basic model assumes that commanders are just like any other player, and that they have the same contribution to the outcome of the game as any other player. This isn’t necessarily a bad assumption, I’ve seen many games where an unusually vocal and motivational player other than the commander was able to call plays and lead a team to victory.
The much worse assumption however is that the same skill sets apply for being a commander or a player. Players that can assassinate fades and dodge skulks might be useless in the command chair, so it doesn’t make much sense to use the same skill values for both. To fix this, we give each player a separate skill level that indicates their skill at commanding. To distinguish it from the other skill level, we’ll call it 
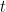

This makes a few questionable assumptions for simplicity. The model will still do useful things even if these assumptions are false, but they do indicate areas where the model won’t perform well.
1. The magnitude of the impact of the commander does not depend on the size of the game.
2. Playing marine commander is equivalent to playing alien commander.
3. A good commander with a bad team vs a bad commander with a good team is expected to be an even match. I suspect this isn’t true because there are few ways that a commander can influence the outcome of the game independently of their team, such that a bad team probably critically handicaps a good commander, and as such it might make sense to use quadratic terms instead.
How do we balance the teams in a real game?
NS2 had a feature where players could vote to “Force Even Teams” but it was generally unpopular. The skill values weren’t very accurate, and the strategy used to assign players had some undesirable properties. It used a simple heuristic to assign the players since the general problem is NP-complete. Because it reassigned all players, they would find themselves playing aliens when they wanted to play marines, or vice versa, and would switch back right after the vote. To fix this, we designed an algorithm that minimizes the number of swaps that occur to reasonably balance the teams.
- Optimize the team assignments of the players who have not yet joined a team. You can do this using whatever method you wish.
- Consider each pair of players. Find the pair where swapping them minimizes the absolute value of the skill difference. Iterate until there is no pair that reduces the absolute value of the skill difference.
While this greedy heuristic of swapping only the best pairs one at a time may be a poor solution for coming up with the optimal balanced teams, it is great for keeping as many players as possible happy with the team assignments. Because the swap chosen is the one that minimizes the objective function the most, we can get quickly to a local optima by swapping very few players.

You have made a (good) assumption that there are at least two skills that a player may have (FPS vs Commander).
The problem is I don’t think two skills are sufficient to model player ability.
For new players there is a clear bias towards marines (most new players can shoot better than they can wall jump). Even for with skilled players there can be a clear bias (although for some players it is for aliens).
Additionally there are combinations, for example I played on a server where 2 players were very vocal about going “lerk pack” (flying round together) as soon at they had res.
By itself it may not have been too difficult to counter, but it acted as a rallying cry for the rest of the team to follow them in, hence with both those players on the same team there was a significant chance of a win.
Your point about only using the winning/losing to determine the team balance was a good one.
Perhaps there is a simple solution:
Each time a new round start evenly divide up the winning team between aliens and marines.
I realize that that will cause contention (players that want to play a particular side), therefore it might be worth having a 30 second team pick period at the start of each round where everyone can specify:
Marines, Aliens or Random.
Critically the vote is not disclosed to other players until the 30 second period is up.
If the winning team is “jumbled” okay everyone can have their ideal pick.
Otherwise the server will need to force assign some players at random.
I realize even this proposal can be “gamed”, but if you allow players to pick there side of choice its near impossible to prevent a small group (2-3) of very highly skilled players from stacking a server.
Hello Ryan, is the 3.0 hiveskill open source? If not, is it possible to share it as one of our servers which has been unranked/excluded from hive 3.0. We’re currently hosting our own trueskill, but we would like to check if Hiveskill is better.
Best Regards
No it isn’t, but if you want to implement it, I’d be happy to code review the math and help sanity check what it does.
Sorry for the late reply, didn’t realise my mail flagged it as spam. Thank you for your kind gesture, I’ll inform the modders and se what we’ll do. 🙂