TL;DR
To describe one fraction, use a binomial. To describe your uncertainty about that fraction, use a beta. To describe a collection of related fractions, use a beta-binomial.
What’s the Right Way to Aggregate Fractions?
Imagine you’re in the middle of building something awesome, when you realize that you have a problem that sounds something like one of the following:
-
A reddit user has submitted a bunch of URLs. Each one has a different number of upvotes and downvotes. How good is this user?
They’ve just posted a new link. That link has one downvote. Do we show it to more people or let it die in obscurity?
-
An author on a news site has written a collection of articles, each with a different bounce rate. How effective is this writer at driving traffic to the rest of the site?
They’ve just posted a new article. Should we promote it?
-
A supplier produces a bunch of different products sold on your website. Each one has a different average star rating. How good are the products from this supplier?
They’ve just added a new product to their catalog. How should we rank this against items from other suppliers that already have ratings?
In all of these situations you’ve measured a whole bunch of fractions. You think that these fractions have something in common because the same entity is responsible for them, but you don’t think they are exactly the same. Even if you had an infinite amount of data, each item would still be different. The collection of things made by each user or author or supplier has a range of quality. How can we accurately describe this range? Once we’ve described it, how can we use this to guess the quality of the next thing this entity does?
Henceforth, I’m going to use the reddit example, but it applies to a ton of different situations. For instance, It is one of the most common statistical problems we encounter in search.
What’s Wrong with Something Simple?
We have a whole bunch of fractions. We want to summarize them in some way to describe each user. Aggregating them seems like the reasonable thing to do. How could we aggregate them?
-
Add all the numerators, add all the denominators, and divide?
Consider the case of a notorious spammer who gets downvoted every time he posts, except one time he gets lucky, and a post takes off. The average for this spammer would be high, even though almost all of his submissions are horrible.
-
Count each fraction as 1 and take the average of all of them?
Consider a user who regularly makes fantastic comments with lots of upvotes, but periodically gets into a flame war with a single user who downvotes every comment in the thread. Those comments with a single downvote would get the same weight as the great comments, even though they represent the opinions of a very small number of people.
-
Weight each fraction by its denominator (equivalent to #1) except cap the denominator at something reasonable so that the average isn’t dominated by a single fraction?
Now we’re getting somewhere. This is how the system we’re going to derive behaves. It figures out the cap automatically, and it’s not quite a cap, but if you want to implement the simplest approximation of the Right Way™, weight each fraction by
(where
is some arbitrary constant, and
is the denominator) and call it a day. However, the Right Way™ is much power powerful than this so read on!
Reddit’s karma system currently accumulates the total number of upvotes minus downvotes. This is good for encouraging users to post, but not at predicting the quality of a user’s posts. We can do better.
Dealing with One Fraction: The Binomial
Before we work on inferring something from a collection of fractions, let’s figure out how to deal with one fraction.
Any time you are measuring a fraction and describing it as a probability, you are talking about a binomial distribution. If you test something 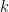

 In the reddit example,
In the reddit example, 
What can we conclude about
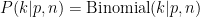

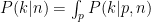
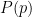


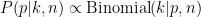

The difference between this formula and the one we started with is that
We’ll get back to the beta distribution in a second. For now we’re just concerned with


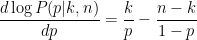



Wow, that’s about as intuitive as it gets. When you estimate the probability of an event as the fraction of times it happened (
Now we know how to deal with one fraction, and how to guess its
Representing Uncertainty about a Fraction: The Beta Distribution
The beta distribution is a smooth distribution over the interval ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
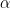
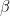
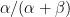


Notice that the beta distribution has the same form as the binomial distribution, but with 




When we assume we have no information about the distribution of


As above, we’ll change the conditioning by noting that the prior probability 
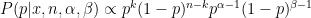

From the knowledge that this is a probability distribution and thus integrates to 1, we can put in gamma terms that we know will normalize the distribution and change

Look how nicely that collapsed! We end up with another beta distribution for
This makes the beta distribution an extremely convenient choice for representing the range of quality of each user! If we express that range of quality as a beta distribution, then we can easily make good guesses about the quality of a post no matter how many votes it has by maximizing the above formula! Our best guess as derived in the previous section becomes
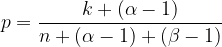
So if we have a beta distribution for each user, doing the right thing to rank their posts is now exceedingly easy. Notice how the 
To figure out the beta distribution for each user, somehow we have to infer it from the collection of numerators and denominators of their posts. We’ll do this using the combined distribution.
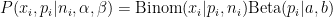
This combined distribution of binomial samples generated from a beta is called the Beta-Binomial.
How do we fit a Beta-Binomial?
The joint probability of the data and the values of

If we knew the values of 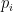
This is a perfect opportunity to use Expectation Maximization, an optimization technique that lets us alternate between fitting
Using the “Soft EM” version of the algorithm, we’ll be iteratively maximizing
![\displaystyle \sum_i\text{E}_{p_i|k_i,n_i,\alpha,\beta}[\log P(k_i,p_i|n_i,\alpha',\beta')]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_i%5Ctext%7BE%7D_%7Bp_i%7Ck_i%2Cn_i%2C%5Calpha%2C%5Cbeta%7D%5B%5Clog+P%28k_i%2Cp_i%7Cn_i%2C%5Calpha%27%2C%5Cbeta%27%29%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
where 

As we discussed above, from a binomial observation (
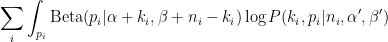
![\displaystyle \sum_i\int_{p_i}\text{Beta}(p_i|\alpha + k_i, \beta + n_i-k_i)\left[\log \text{Binom}(x_i | p_i, n_i) +\log\text{Beta}(p_i | \alpha', \beta')\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Csum_i%5Cint_%7Bp_i%7D%5Ctext%7BBeta%7D%28p_i%7C%5Calpha+%2B+k_i%2C+%5Cbeta+%2B+n_i-k_i%29%5Cleft%5B%5Clog+%5Ctext%7BBinom%7D%28x_i+%7C+p_i%2C+n_i%29+%2B%5Clog%5Ctext%7BBeta%7D%28p_i+%7C+%5Calpha%27%2C+%5Cbeta%27%29%5Cright%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
The first term is a data dependent constant that doesn’t depend on

If you know a bit about information theory, this term should look familiar. It’s the negative of the cross entropy between 

Let’s break apart the Beta inside the log.


![\displaystyle N\log\frac{\Gamma(\alpha'+\beta')}{\Gamma(\alpha')\Gamma(\beta')}+\sum_i \alpha'E_{p_i}[\log p_i] + \beta'E_{p_i}[\log 1-p_i]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+N%5Clog%5Cfrac%7B%5CGamma%28%5Calpha%27%2B%5Cbeta%27%29%7D%7B%5CGamma%28%5Calpha%27%29%5CGamma%28%5Cbeta%27%29%7D%2B%5Csum_i+%5Calpha%27E_%7Bp_i%7D%5B%5Clog+p_i%5D+%2B+%5Cbeta%27E_%7Bp_i%7D%5B%5Clog+1-p_i%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
These expectations of the log
![\displaystyle N\log\frac{\Gamma(\alpha'+\beta')}{\Gamma(\alpha')\Gamma(\beta')}+\sum_i \alpha'[\psi(\alpha + k_i) - \psi(\alpha + \beta + n_i)] + \beta'[\psi(\beta+n_i-k_i) - \psi(\alpha + \beta + n_i)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+N%5Clog%5Cfrac%7B%5CGamma%28%5Calpha%27%2B%5Cbeta%27%29%7D%7B%5CGamma%28%5Calpha%27%29%5CGamma%28%5Cbeta%27%29%7D%2B%5Csum_i+%5Calpha%27%5B%5Cpsi%28%5Calpha+%2B+k_i%29+-+%5Cpsi%28%5Calpha+%2B+%5Cbeta+%2B+n_i%29%5D+%2B+%5Cbeta%27%5B%5Cpsi%28%5Cbeta%2Bn_i-k_i%29+-+%5Cpsi%28%5Calpha+%2B+%5Cbeta+%2B+n_i%29%5D&bg=%23ffffff&fg=%23000000&s=-1&c=20201002)


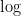
We’re ready to take some derivatives.

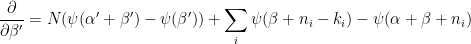
When we set the partials to 0 and solve we get particularly beautiful relationships.


Unfortunately, solving this involves inverting the digamma function, which everyone seems to cite someone else for. I’m no exception. At this point I’ll refer you to Thomas Minka’s Estimating a Dirichlet Distribution where he works out both fixed point (slow) and newton iteration (fast) methods to solve for alpha and beta from this set of equations.
Without worrying about how to solve the terms on the left side, there’s a lot we can infer just looking at the expressions. Notice how the right side is just the average of a statistic collected over all of the samples. 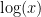

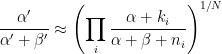
This tells us that the mean of the beta will be approximately the geometric mean of the smoothed values of
Let’s see what else we can figure out from these expressions. Consider the case where we’ve only measured 1 binomial sample, or all the binomials we’ve measured have the same 

We didn’t include a prior for 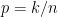
It’s doing the right thing, there isn’t a bug in our math. The delta function at that value is the maximum likelihood estimate when all of the binomials have the same
Unfortunately, the beta distribution doesn’t have a convenient conjugate prior for us to use. Instead, let’s borrow the idea of “pseudocounts” from the binomial example. Our fit is expressed as a nice summary statistic averaged over all the binomials, and we showed how these represent cross entropies from the beta implied by each binomial. Let’s just add some fake ones. We’ll make up a beta with parameters 

These collapse nicely with our previous derivation, and turn into an equally convenient update rule. These terms force convergence, because they don’t update on each iteration.
![\displaystyle\psi(\alpha')-\psi(\alpha'+\beta')=\frac{1}{N+M}\left[M(\psi(\alpha_\emptyset)-\psi(\alpha_\emptyset+\beta_\emptyset))+\sum_i\psi(\alpha+k_i)-\psi(\alpha+\beta+n_i)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cpsi%28%5Calpha%27%29-%5Cpsi%28%5Calpha%27%2B%5Cbeta%27%29%3D%5Cfrac%7B1%7D%7BN%2BM%7D%5Cleft%5BM%28%5Cpsi%28%5Calpha_%5Cemptyset%29-%5Cpsi%28%5Calpha_%5Cemptyset%2B%5Cbeta_%5Cemptyset%29%29%2B%5Csum_i%5Cpsi%28%5Calpha%2Bk_i%29-%5Cpsi%28%5Calpha%2B%5Cbeta%2Bn_i%29%5Cright%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
![\displaystyle\psi(\beta')-\psi(\alpha'+\beta')=\frac{1}{N+M}\left[(\psi(\beta_\emptyset)-\psi(\alpha_\emptyset+\beta_\emptyset))+\sum_i\psi(\beta+n_i-k_i)-\psi(\alpha+\beta+n_i)\right]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cpsi%28%5Cbeta%27%29-%5Cpsi%28%5Calpha%27%2B%5Cbeta%27%29%3D%5Cfrac%7B1%7D%7BN%2BM%7D%5Cleft%5B%28%5Cpsi%28%5Cbeta_%5Cemptyset%29-%5Cpsi%28%5Calpha_%5Cemptyset%2B%5Cbeta_%5Cemptyset%29%29%2B%5Csum_i%5Cpsi%28%5Cbeta%2Bn_i-k_i%29-%5Cpsi%28%5Calpha%2B%5Cbeta%2Bn_i%29%5Cright%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
The nice thing about these expressions is how intuitive they are. The difference of digammas may seem like a strange statistic, but finally you’re just averaging this function over all of your data, and then inverting it, just like you would average the values to compute a mean, or average the squared error to compute a variance.
Because this fitting process is expressed in terms of a summary statistic, we can easily implement a streaming version of this algorithm without any extra derivation. We buffer some data, fit the beta, then assume that these summary statistics of the difference of digammas are good enough to describe the points we’ve seen so far. We then discard those points, and keep only the current beta and a weight to reflect how much data we’ve already processed. This beta and weight posterior for our current fit become the prior for fitting the next buffer of data.
This is the advantage of this approach over integrating out
Simulated Data

In these charts I’ve simulated what real data might look like. In order to see the difference between them, there are two sets of plots, one for a beta-binomial, and one for a binomial.
Beta-Binomial
- Sample
- Sample
,
- Sample
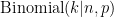
Binomial
- Sample
- Sample
.
This is repeated 10,000 times. Both distributions have the same mean. The interesting pattern is in their spreads.


In the Beta-Binomial, the distribution continues to spread out as


As


These graphs are here solely to demonstrate the futility of understanding these distributions through a histogram. It is a very poor tool to understand a fraction computed over varying
In the Real World
Worry more about what you are measuring than how you are measuring it. Getting the math right is a secondary consideration. You do this stuff after you have something simple that basically works. Break out the big guns to make it better, not in the hopes that it will make something work if the stupid version doesn’t already do pretty well.
For instance, In this article I’ve assumed that the ratio of upvotes to votes is the relevant measure of quality, but it may not be the best. It might be more interesting to measure the ratio of upvotes to impressions. Or maybe to measure independently the ratio of upvotes to all votes, and the ratio of all votes to impressions. There are many aspects of a user that you could (and should) attempt to describe in a complete system.
However, whatever aspect you are measuring, if you can express it as a fraction, chances are this is the technique you’ll want to use to describe it.

This is a great post and exactly what I’m looking forward, although perhaps a bit complex. In the special case where all n_i are the same (although not relevant for you), the method of moments provides a simple technique as sketched out on wikipedia’s Beta-Binomial page. In fact, most articles I find discuss only the case where all n_i are the same. Do you know if its possible to do modified method of moments that would also solve this problem (even if it’s only a second order approximation)?
Thanks!
In the code that I’m preparing to release, I initialize using moment estimates with varying n, though it’s somewhat hacky. The mean is easy. The variance of the beta I approximate using the overdispersion. The wikipedia article relates the overdispersion parameter to the variance of the betabinomial http://en.wikipedia.org/wiki/Beta-binomial_distribution#Moments_and_properties. I estimate the overdispersion by inverting that function on each individual squared error, then guess the variance of that estimate hackily, and compute the weighted average over all the samples weighting by the inverse of the variance of each estimate.
It works well as an initialization, enough to speed things up 20x over what I was doing before, but it’s not something I’m terribly proud of. 🙂